
Tekoäly ja tutkijan kultainen kosketus
Helsingin yliopiston biofysiikan professori Ilpo Vattulainen ymmärsi neuraaliverkkojen ja itseorganisoituvien karttojen hyödyt jo vuosituhannen alussa, vaikka silloiset laskennalliset ja teknologiset rajoitteet pakottivat käyttämään niitä vain pieniin ongelmiin. Tänään tutkijat käyttävät erilaisia AI-sovelluksia jokapäiväisinä työkaluinaan nimenomaan suurien tietomassojen tutkimiseen.
Tekoäly eli AI (Artificial Intelligence) on Vattulaiselle kattotermi, jonka alle mahtuvat kone- ja syväoppimiset ja muut AI-menetelmät, joita voi käyttää eri konteksteissa ja ongelmissa.
– Tutkija miettii aina ensimmäiseksi ongelmaa ja vasta sen jälkeen, mikä lähestymistapa siihen voisi toimia. Menetelmiä on paljon ja osa niistä toimii yhteen, osa toiseen. Aika harvoin on semmoista Graalin maljaa, jota voisi käyttää kaikessa tutkimustyössä – paitsi tietysti tutkijan omat aivot.
Vattulainen vetää tutkimusryhmää laskennallisen elämäntieteen alueella, jossa laskennallisia menetelmiä käytetään terveyden edistämiseen.
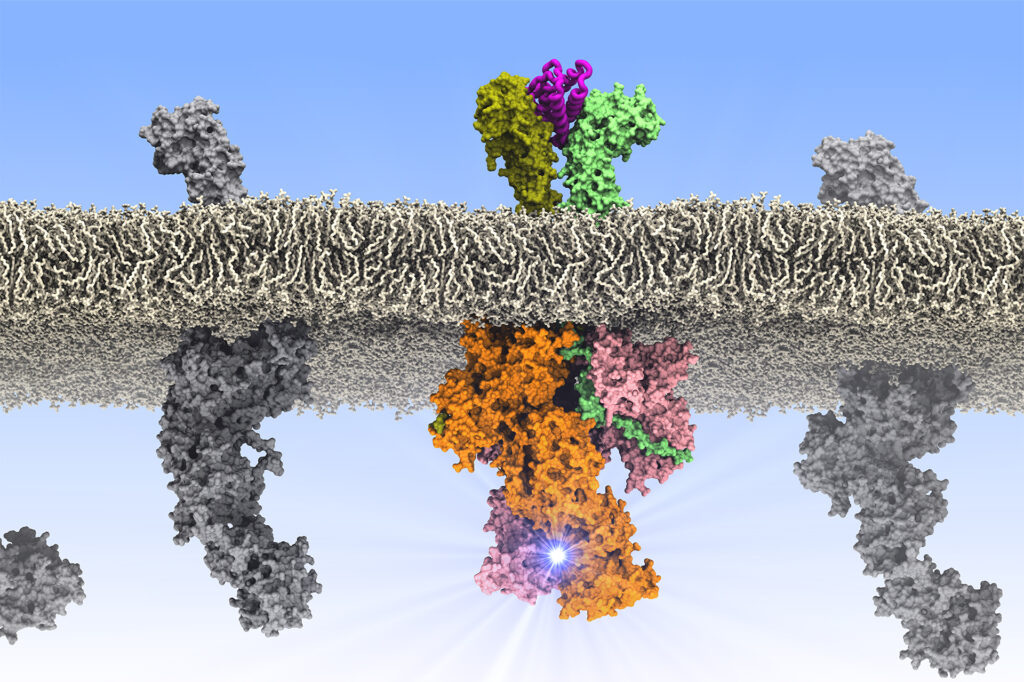
– Työ on pitkälti biologisten molekyylitason ilmiöiden mallinnusta ja näiden mallien toimintaa tutkivia simulaatioita, joiden avulla voidaan selvittää, ja myös ennustaa, kuinka molekyylit, kuten proteiinit, käyttäytyvät eri tilanteissa ja ohjaavat elimistön toimintaa, Vattulainen selittää.
– Mallin voi tehdä vaikka pahvista tai legopalikoista, mutta simulaatioissa tarvitaan ehdottomasti tietokonetta.
Tutkijat analysoivat AI-menetelmillä datamassoja mallinnuksen tarpeisiin. Vattulainen muistuttaa, että maailmankaikkeudessa on järkyttäviä määriä dataa ja keskeinen ongelma on löytää oikeat tutkimuskohteet aineistosta, joka on yleensä hirvittävän kohinaista.
– Joillakin tutkijoilla on kultainen kosketus, jolla he löytävät nopeasti asioiden ytimen ja havaitsevat systeemin käyttäytymisestä poikkeavat hiljaiset signaalit. Sitä ei kuitenkaan ole kaikilla. Ja jos ei pääse edes alkuun, on todella vaikeata tehdä analyysiä millekään datasetille, Vattulainen kuvaa tutkijan keskeistä haastetta.
– AI-menetelmät auttavat löytämään kohinasta sen kaikkein tärkeimmän eli ne hiljaiset signaalit, joiden ympärille voi alkaa rakentaa kohinasta vapaata systeemin käyttäytymisen mallia.
Datan laatu avainkysymys
Kun malli on hahmollaan, sitä lähdetään opettamaan syöttämällä sille valtavia määriä dataa, jonka avulla se kehittyy tarkemmaksi. Kun on rakennettu tekniikka tai menetelmä, joka kohdistuu johonkin tiettyyn datajoukkoon, sitä voi soveltaa myös muihin datajoukkoihin.
– Voimme esimerkiksi tutkia, miten lääkeainemolekyylikandidaatit tarttuvat johonkin tiettyyn proteiiniin: saavatko ne siinä aikaan rakenteen muutosta ja ajavatko ne sitä haluttuun toiminnalliseen ja aktiiviseen tilaan – eli toimiiko jokin lääkeaine sillä tavalla, että se ylläpitäisi sen proteiinin toimintaa, Vattulainen kuvaa.
– Siinä tarvitaan koneoppimisalgoritmia, joka vertailee mallinnettua proteiinia sekä ilman lääkeainetta että lääkeaineeseen tarttuneena ja kertoo, tapahtuuko siinä relevanttia muutosta. Samalle algoritmille voitaisiin myös syöttää muitakin mallinnettuja molekyylejä, joiden joukosta se poimisi potentiaalisia kandidaatteja jatkotutkimuksiin ja hylkäisi ne, joilla ei ollut minkäänlaista vaikutusta.

Toiset AI-menetelmät opetetaan haluttuihin tehtäviin tietyllä datajoukolla. Toisille taas riittää, että niille syötetään dataa, jonka ne käyvät läpi ja tekevät niille jonkin tehtävän, esimerkiksi luokittelevat ne havaitsemiensa säännönmukaisuuksien perusteella.
– Tällaisia tehtäviä on paljon. Nämä itseoppivat menetelmät oppivat siinä projektin aikana ja pystyvät tekemään tiettyjä funktioita.
Koulutusvaihe ja sen datan laatu, jota järjestelmälle syötetään menetelmien koulutusta tai analyysia varten, on Vattulaisen mielestä AI:n käyttäjän suurin haaste, josta ei puhuta tarpeeksi keskusteltaessa AI:n luotettavuudesta.
Esimerkiksi käy laskennallisen elämäntieteen ytimessä oleva kysymys siitä, millä tavalla proteiinit laskostuvat ja muodostavat toiminnallisen rakenteensa ja miten tämä rakenne muuttuu esimerkiksi mutaatioiden tai muiden molekyylien vaikutuksesta.
– Proteiinien rakenteen laskennallinen ennustaminen ei onnistu, jos dataa on vähän, vaikka se olisi loistavaa. Eikä surkean datan kohdalla auta yhtään, vaikka sitä olisi valtavasti. Mutta jos on paljon loistavaa dataa, niin onnistumisen todennäköisyys on korkea.
AI tulee koko ajan viisaammaksi. Se ei kuitenkaan vapauta käyttäjäänsä vastuusta lopputuloksen suhteen.
Perinteisillä kokeellisilla menetelmillä tehtävään proteiinin rakenteen määrittelyyn kuluu aikaa muutamista kuukausista muutamaan vuoteen. Sen vuoksi tutkijat käyttävät tekoälypohjaista ja paljon hypetettyä AlphaFold-työkalua, joka ennustaa proteiinin emäsjärjestyksestä sen kolmiulotteisen rakenteen
– Tämän ennustamisen oikeellisuus on sitten ihan oma kysymyksensä ja riippuu siitä, kuinka paljon kokeellisesti tuotettua koulutusdataa sillä ylipäätään on käytettävissään.
Joissakin proteiiniperheissä koulutusdataa on kymmenistä tuhansista proteiineista ja ohjelman ennustama rakenne on hyvin lähellä oikeaa. Sitten on proteiiniperheitä, kuten solukalvoihin upotettuja proteiineja, joiden rakenteista tunnetaan vain muutamia satoja tai ei ainuttakaan. Ne ovat kuitenkin tutkimuksellisesti tärkeitä, koska niihin kohdistuu noin puolet kehitettävistä lääkeaineista.
– Näitä rakenteita tunnetaan muutama tuhat, mutta yksittäisillä proteiiniperheillä niitä saattaa olla vain sadan luokkaa. Rakenteen arvailu sellaisen määrän perusteella menee todennäköisesti pieleen, enkä luottaisi näihin arvauksiin ainakaan vielä tällä hetkellä.
Vapauttaa aikaa ajatteluun
Joka tapauksessa AI tehostaa ja nopeuttaa tutkijoiden työtä ja päästää käsittelemään jättiläismäisiä datamassoja, joita ei ennen ole voinut ajatellakaan.
– Tekoälystä on merkittävää apua esimerkiksi rakennettaessa simulaatiota varten jonkin ison proteiinin mallia, jonka rakenne on jouduttu määrittelemään kokeellisesti palasina. Niistä on rakennettava tietokonesimulaatiota varten yhdistetty tiedosto, jossa atomien väliset sidokset on kuvattu yksityiskohtaisesti.
Palasten yhdistämiseen tiedostoksi kuluu helposti 2–3 päivää, ja työ on erittäin virheherkkää. Tekoälypohjaista ohjelmistoa käytettäessä tutkijan sen sijaan tarvitsee vain syöttää proteiinin emäsjärjestys ja painaa tietokoneen näppäimistöllä enteriä.
– Sen jälkeen voit mennä kahvihuoneeseen pariksi tunniksi keskustelemaan kollegoiden kanssa vaikka uusista projekteista ja sieltä palatessasi ohjelman tuottama rakenne on valmis. Se toki yleensä vaatii tutkijan tekemää pientä korjailua ja hienosäätöä, Vattulainen kuvailee.
– Sitten ajat tietokoneella sitä mallia niin, että se on tasapainottanut itsensä ja löytänyt oikean rakenteensa. Sen jälkeen se kelpaa systemaattiseen tuotantoajoon.
Säästynyt työaika kannattaa Vattulaisen mielestä käyttää esimerkiksi ajatteluun.
– AI suorittaa yksinkertaiset ja toistuvat automatisoitavat prosessit ja tulee koko ajan viisaammaksi. Se ei kuitenkaan vapauta käyttäjäänsä vastuusta lopputuloksen suhteen. Se on vain työkalu, joka antaa tietynlaisia ehdotuksia. Sen jälkeen tutkija – eli se ainoa taho, jolla on asiasta kokonaisnäkemys päässään – päättää, mitä hän sillä ehdotuksella tekee eli käyttääkö hän sitä sellaisenaan, muokattuna vai hylkääkö hän sen kokonaan.
Kuka varmistaa datan laadun?
Vattulaisen tutkimuskentällä dataa saadaan omasta tutkimuksesta, yhteistyökumppaneilta ja julkisista avoimista lähteistä.
– Itse tuottamamme datan kohdalla meidän täytyy luottaa oman kokemuksen tuomaan vaistoon ja osaamiseen, ja siihen että ryhmä on koulutettu tekemään oikeita asioita. Meillä on myös erittäin kova itsekritiikki, emmekä edes julkaise tuloksia, joihin emme luota, Vattulainen sanoo.
– Yhteistyökumppaneiden kohdalla peruslinjamme on, että hakeudumme yhteistyöhön itseämme parempien kanssa, sillä se mahdollistaa oman osaamisen kehittymisen. Parhaimmilla toimijoilla on erittäin vahvat omat kontrollinsa ja käytäntönsä, joiden avulla he pysyvät huipulla.
Kolmas lähde on open data eli se mikä on avoimesti saatavilla verkossa. Sen kanssa vastuu ymmärtämisestä siirtyy kuuntelijalle.
Avoimen datan käyttö edellyttää kykyä arvioida kriittisesti, voiko johonkin dataan luottaa vai ei.
– Tämä on se hankalin kohta. Eri lähteistä voi löytää dataa järkyttäviä määriä, mutta voiko sitä käyttää sillä tavalla, että siitä on hyötyä? Toisaalta huonostakin datasta voi olla se ilo, että se herättää uusia ideoita siitä, miten sitä voitaisiin käyttää muissa yhteyksissä.
Mitään konsensusta ja kokonaisnäkemystä ei muutenkaan vielä ole, miten AI-puolen IPR-asioihin pitäisi suhtautua. Oman IPR:n suojaamiseksi on välttämätöntä tietää käytetyn työkalun toiminnan periaatteista ja esimerkiksi palvelimien sijainnista.
– Olemme varoittaneet työryhmän sisällä tutkijoitamme siitä, että mitään luottamuksellista tekstiä ei pidä syöttää Chat-GPT:n kaltaisille työkaluille, joita ylläpidetään ulkomaisilla palvelimilla ja joiden toiminta on käyttäjän näkökulmasta musta laatikko, Vattulainen sanoo.
– Kaikki tehtävät, joita niille annetaan, ovat niille dataa, jota ne käyttävät jatkossa saamiensa tehtävien ratkaisemiseen. Sen vuoksi ei kannata yrittää parannella englanniksi kirjoitetun patenttihakemuksen kieliasua jollakin Chat-GPT-tyyppisellä ohjelmalla. Sen kun teet, niin se on sen jälkeen julkista dataa.
Lue kaikki tekoälyä käsittelevät Valokeila-kokonaisuuden artikkelit:
Tekoäly etsii varhaisia signaaleja hyönteistuhoista
Enemmän onnistumisia lääketutkimukseen